I have all the advertisements databased and a scraper in place to gather new data form the site as it is posted. I have also begun exploring the data and tagging relevant features that I will want the AI to extract from the transcripts. A couple of interesting things I’ve found in the data so far:
There is a strong seasonality to runaway events:
There are a couple of exceptional years where runaway events occurred at a high rate, 1828 and 1854. 1854 could be an outlier year because of the tense political climate which began then, it was the start of bloody Kansas, I’m not certain why 1828 would stand out but it could be from the Tariff of 1828 which hurt the southern economy creating more opportunities for escape attempts.
I expect to have more summary analysis for you this week which will be based on the portion of the advertisements from the site that have complete features listed. I will also start building some proof of concept models and begin testing the accuracy of AI at extracting certain features.
Yes, the ads are unique, however there are two kinds of ads:
- Posted by enslaver, searching for a runaway
- Posted by a jailer after a runaway was captured
Ideally we would like to try ad pair the two to eliminate the possibility of two ads appearing for a single runaway event but the ads themselves are scant on details so trying to match them up is really just guessing. I think the best way to proceed is to treat both groups as separate samples of the total ground truth dataset with the understanding that each group may contain overlap.
Something else I was thinking about is that a single ad poster may run their ad in multiple newspapers, I will check for that occurrence based on transcript similarity and try to eliminate any duplicates.
Also our data could be biased by the survivorship of newspaper archives. What amount of newspapers survived from the 19th century? And for what regions? Answering these questions will require some kind of expertise in the availability of historical documentation from that period. Without this knowledge we may mistake survivorship biases of newspapers for trends in ads.
We can at least color code for jailer or owner with ads in charts.
We can create or known the total number of newspapers avail by year versus the sample we have. Then use that to arrive at an aggregated estimate of advertised runaways.
Looking to infer the prevalence of rape by the keyword mulatto, light skin etc in ads, I could do a text search but those tend to be inaccurate (‘it was light outside when the runaway occurred’ vs ‘the runaway had light skin’) I will probably want to use an AI to find these.
Type of ad is something the AI will need to determine before we can proceed with high level analysis because right now >80% of the ads have not been categorized:
I will make ‘advertisment.type’ my first proof of concept AI model that way we can start high level analysis while I continue work on the other features.
I added a new axis of distinct number of newsapers/year to hopefully explain some outlier ad years based on newspaper availability. Of course this is all coming from the same dataset so it is possible a newspaper existed in a year but did not publish any runaway ads in which case it would not show up in our count even if there is a historical record.
About 20% of the ads are completed which basically means a lot of the features that we want have been extracted by hand, this is good because I will use this for training data in the AI model. There is a field called ‘racial_description’ and here are the top 15 responses for that field. I will need to simplify these categories for our model prior to training (probably into three categories ‘lighter’, ‘darker’, ‘average’).

Also I thought it was interesting that (for the completed ad sample) the average runaway is young (25.72 years old) and male (75%)

I’ve completed a proof of concept version of the ad type classifier AI model. I say ‘proof of concept’ because a lot of the development time for these models goes into hyper-parameterizing basically fine tuning that creates additional accuracy, this can be very time consuming so POC models are a good place to start establishing a method before making the time investment.
This POC model produced an accuracy of ~96% and classified the 27k ads as 93% enslaver and 7% jailer.

I’m going to start working on demographic POC models now starting with multiple v single runaway classification and then going on to gender, racial_description and age.
Here are some previous charts I sent you but with the new ad classification:

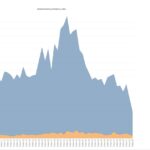
I finished the construction of multiple v single runaway classification AI, the accuracy for the POC model is 94%.
The single runaway ads will be pushed directly into an AI that will return our desired demographic data. The multiple runaway ads will need to be split into relevant bodies of text that contain the descriptors for each runaway before being pushed into the same AI. We can then aggregate and study the results.
As I have started constructing this system I am coming across some data quality issues that need attention.
-First of all many of the transcriptions are missing, these ads slipped past my original criteria because their transcription fields are populated but they contain things like “[illegible]” or “NAN”
-Some of the ads have been entered more than once despite the fact that they are from the exact same image, interestingly their transcriptions contain differences that avoid simple duplicate text detection.
-Some ads are published in multiple newspapers (as we discussed) but their transcriptions are different as some sentences have been slightly reworded perhaps by the editor or printer.
Here is how I plan to correct these data quality issues:
1. Begin work on a transcription program to process the ads with missing/incomplete transcriptions.
2. Create an algorithm that compares original transcription images and tags duplicates.
3. Create an algorithm that uses Cosine Similarity [en.wikipedia.org] to detect rephrased duplicate ads.
The results from this cleaned data will be databased and then used in all training and analysis. Unfortunately, this data cleaning will need to be done prior to any more analysis progress. I will prioritize items 2 and 3 so that we can at least perform analysis on most of the ads before finishing item 1.
There are 27k ads, right now there are about 3k that I have been using for training. I would estimate that about 50% of the 27k ads will need to be re-transcribed. I’m still working on the duplicate detection algorithms so ill get back you with those figures.
Yes, ill create a log of errors so we can share it with the Freedom on the Move people, do you have any contact with them? If so I would love to have a call with them and just get a little more background on where the data comes from and how they are generating their transcriptions (program? Crowdsourced?). Maybe they would be willing to share some resources with me?