
As mentioned I have completed development of the transcript selector as well as the event generator. Event generation is particularly important because ads are run in a series and often times in multiple newspapers spanning up to nine months for some of the longer running ads. Without accurate event generation you will overrepresent the same runaway event multiple times creating unusable results. Originally I relied on the FotM event ids but have since discovered that these are terrible, our event generation measures the cosine similarity between the text of every ad to find pairs, in my checks I have found it to be extremely reliable and with that framework now in pace and about 13k reliable transcripts we have mapped out ~8k distinct events. From these events I have generated the following updated charts:
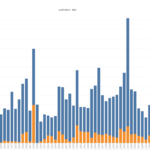
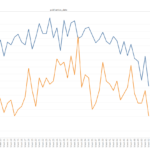
As you can see 1828 and 1854 still stand out as outliers but not to the extent that they did with the FotM event IDs. Seasonality remains a factor as before but with a better jailer sample we can see jailer seasonality lags enslaver as you would expect from the lag between runaway events and capture events.
I’m continuing to develop new AI POC models on this data with mixed results. The techniques im using to design the models come from other text based projects ive worked on in the past but none of those have text inputs this long (the last text AI I built was for LNG ship stated destinations those were only 90 characters). My POC models for things like Jailer v Enslaver ad types and single v multiple runaways work pretty well using these techniques but other models I’ve built which try to extract specific information from the ad like the amount of the reward offered don’t seem to work as well as I expect they could.
We could always just brute-force the problem with MTurk but before we resort to that I would like to give some more advanced AI techniques a try. I would like to invest some time in learning some of the proven techniques related to AI unstructured text processing. This time investment (probably a couple of weeks) will unfortunately slow the project down but I think in the long run it gives me some additional AI expertise for my toolbox and in the near term it makes this project cheaper, more flexible (we can easily tweak the AI to give us new features but doing the same from MTurk would require an entirely new batch to be run on the entire dataset) and easier to scale. In my opinion this is the biggest benefit of doing things in house as opposed to outsourcing, we develop new skills and talents that we can apply elsewhere, in this case I could see this new knowledge being applied in the future to something like a pipeline notice project.
While I’m developing these more advanced models we can send the remaining ~14k ads to MTurk for transcription. I don’t think 3 jobs per ad will be necessary, 2 is enough. This will cost about $14k to run.
Let me know your thoughts.