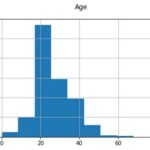
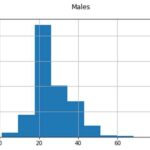
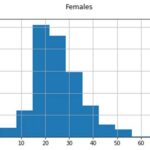
Hey Bill, here is some detail about how I am developing the runaway AI.

The AI must accomplish four tasks:
1. Annotate the individual words of the ads.
2. Group the annotations into phrases.
3. Determine number of runaways and assign phrases by runaway.
4. Clean and format phrases.
1. Annotation:
The AI iterates over every word in the ad and categorizes it into one of our feature groups or a null category. The method I chose for doing this is a non-sequential model which takes three inputs. Two of the inputs are at the word level and one is at the character level so that the model can process names and misspellings as well as clues from commas and periods. The two word level inputs are at different scales one I call the phrase scale which looks at the word in question as well as the one before and after it and the context level which looks at five words before and after the one in question. The character input is at the phrase scale.
2. Grouping:
The grouping output will be a 0 or 1 secondary output from the annotation model which will designate if the word after the one being examined should belong to the same group.
3. Assignment:
The number of runaways will be determined logically based on the number of unique runaway names and features mentioned in the ad. Each unassigned feature will be run through an AI model which will take as an input the text of the ad, placement of the feature in question and its position relative to the runaway names. The scores will be compared and ultimate assignments will be made logically (for example one runaway cannot have two different ages, so if there are two runaways use the one that the AI determines more likely and assign the other to the other runaway.)
4. Cleaning and Formatting:
All features are extractions of the text and so different formats are used from one ad to the next (for example a reward could be ‘$10’ or ‘Ten Dollars’.) I will test out various AI and logical methods to clean up the features but MTurk might be a good option here.
AI development is a mix of art and science and the process is subject to change based on experimentation but this is my development plan as of right now. I’m currently working on items one and two and I’ll send you updates as I make further progress.
Let me know if you have any questions.
Thanks,
Eric Anderson, CFA
Quantitative Analyst
Skylar Capital Energy Global Master Fund LP
(713) 341-7985 work
(281) 606-9371 cell