Ok, for newspapers that match an existing one in your system ill tag it with the correct ID, for new newspapers ill try and grab your requested fields from elsewhere in the book so you can assign a new ID.
From: Brandon T. Kowalski <kowalski@cornell.edu>
Sent: Thursday, April 23, 2020 9:41 AM
To: Eric Anderson, CFA <eanderson@skylarcap.com>
Cc: Edward Eugene Baptist <eeb36@cornell.edu>; Bill Perkins <BPerkins@skylarcap.com>
Subject: Re: [External] Runaway Project Overview
Hi Eric,
For all Advertisements we need information about the newspaper (3 fields: newspaper name, publication city, publication state).
You can safely record this once and reference it each time this newspaper is used.
In addition to the newspaper info we have a handful of fields we request on initial import. These can be provided in a spreadsheet.
Filename of Image (relative path please)
Publication Date(ISO8601 Please! YYYY-MM-DD)
Page Number
Full Text Transcription
Of these four fields, publication date is always required.
If the advertisement is coming from a book, like the PDFs Ed sent over, then a Filename is not expected but a Full Text Transcription is required.
If the advertisement has a scan then the FTT is optional.
Hopefully this break down makes sense. Please let me know if you need me to clarify anything.
~btk
On Apr 23, 2020, at 10:28 AM, Eric Anderson, CFA <eanderson> wrote:
Thank you for sending these, ill take a look at breaking them up into individual ads. Should I include any other data points besides the newspaper name, newspaper id and publication dates?
My priority right now is on cleaning the existing images, I am also working on some AI feature extraction and will share updates as I make progress. Also we are putting together a website that will aggregate all runaway project notes and correspondence for easy reference by your team, ill share those details once it’s up.
From: Edward Eugene Baptist <eeb36>
Sent: Wednesday, April 22, 2020 6:58 PM
To: Eric Anderson, CFA <eanderson>
Cc: Bill Perkins <BPerkins>; Brandon T. Kowalski <kowalski>
Subject: Re: [External] Runaway Project OverviewThese are great! I’m sharing a link for the pdfs from the books that I mentioned to you earlier. Let me know how these look—they contain several thousand more ads.
https://drive.google.com/open?id=18IHljQo563f5NBdmmAgI1mTwA7QVC95l [drive.google.com]
Great talking to you today. I’m cc’ing Brandon Kowalski, who’s our lead developer.
Ed
Edward E. Baptist
Professor, Department of History
450 McGraw Hall
Cornell University
Ithaca, NY 14853 USA
From: Eric Anderson, CFA
Sent: Wednesday, April 22, 2020 4:31 PM
To: Edward Eugene Baptist
Cc: Bill Perkins
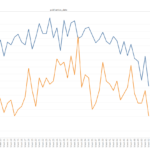
Subject: RE: Runaway Project OverviewHere is a seasonality chart with monthly instead of weekly granularity, it does a better job showing the lag between Jailer and Enslaver ads:
<image001.png>
From: Eric Anderson, CFA
Sent: Wednesday, April 22, 2020 2:31 PM
To: ‘eeb36’ <eeb36>
Cc: Bill Perkins <BPerkins>
Subject: Runaway Project OverviewHello Edward, as discussed here is an overview of our process along with the data we have cleaned so far.
<image002.png>
-Our scraper has pulled your ads, events, runaways, newspapers and other tables and descriptors from your website and stored them on our SQL server. I will add to this an additional process which I will develop to separate from PDFs the new ads you are going to send us.
-Ads are first sent through the Google Vision API (https://cloud.google.com/vision[cloud.google.com]) to get a first draft transcript.
-The first draft transcript is sent to Amazon Mechanical Turk (https://www.mturk.com/ [mturk.com]) for revisions into two distinct final draft candidates.
-The Best Transcription Selector is a program which analyses each final draft candidate and picks the best one to be chosen as the final draft.
-Once an ad_id has a final draft attached it is run through the Event Generator which uses cosine similarity to match the ad to an existing group of ads or create a new event if no match is found.
Ideally I would like to use an AI for feature extraction from the ads but for any feature or ad where the AI fails to deliver what we want we will use MTurk. I’ve attached what ad cleanup we have to far. Ad_ids are the same as yours so you can join with your database if you want to pull further details, for this query I kept the columns simple. There are 27,420 ads, where your transcription is available it is populated in the ‘fotm_transcript’. For the remaining ~15k ads we will be running all of these through the process I described above. ‘transcript_vision’ contains the results of the google vision api first draft, some are pretty good, others need more work. ‘lang’ describes the language detected by google, we are focusing on the English ads for now and will visit the French ads next. ‘transcript_turk’ contains the final draft after going through MTurk, there are about 1k of these, another 1k are done but their batches on MTurk have not completed yet so as soon as those finish ill download and send an update. About 1k ads will need new images due to inadequate size you can identify these as the ads with missing data in the fotm_transcript, transcript_vision and transcript_turk fields, or by multiplying img_px_w and h and filtering by < 20,000. Event_id is our unique identifier generated based on ad similarity.
Here are some of the charts discussed in the call:
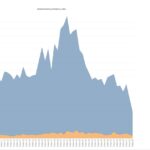
Anomalous number of events in 1828 and 1854
<image003.png>
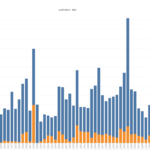
Runaway event seasonality by min publish date.
<image004.png>
Obviously a larger sample might change some of these observations.
I’m looking forward to continuing work on this project. I’ll keep you in the loop as I make progress, please reach out at any time if you have questions and don’t hesitate to give me your candid feedback.
Thanks,
Eric Anderson, CFA
Quantitative Analyst
Skylar Capital Energy Global Master Fund LP
(713) 341-7985 work
(281) 606-9371 cell